이 책의 원서를 Causal Inference in Python 1st Edition 아마존에서 검색을 해 보면 23년 8월 에 출간된 책 입니다. 반년도 안되서 500p 분량을 빠르게 번역되어 나왔기 때문에, 번역된 내용에 대한 품질에 관해 의심이 생길 수 밖에 없었습니다.
하지만 이러한 의심은 1부 내용을 상세하게 읽어보고 난 뒤에는 얼마나 번역하신 분이 열과 성을 다해서 내용을 번역했는지 바로 알 수 있었습니다. 옮긴이의 주석 이 독자가 어려워 할 때마다 구석 구석 모든 곳에서 도움의 손길을 내밀 고 있었습니다.

인과추론을 분석에 도입하는 것이 아직은 초기단계라고 느낄수 있었던 부분이, 관련된 분들이 자신의 지식을 최대한 많은 분들에게 알려주기 위한 많은 활동들을 하고 계셨습니다. 옮긴이가 특별하게 감사드리는 분 중 한분인 **더 유니버시티 오브 노스캐롤라이나 앳 그린즈버러 대학의 박지용 교수님이 만드신 2023년 인과추론 온라인 특강 사이트 가 있고 여기에는 한글로 만들어진 강의 유투브 동영상과 강의자료 PPT 모두 무료로 공개가 되어 있었습니다. 강의내용을 참고하신다면 초보자 분들에게도 많은 도움이 될 것입니다.
1줄평
Python 데이터 분석가 최상급자로 올라가기 위한 인과추론 교과서
전체적인 내용 살펴보기
인과관계 분석을 할 때에는 회귀모델학습 방법을 활용하는 경우가 많습니다.
import torch.nn as nn
def LinearRegressor(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(1, 1, bias=True)
def forward(self, x):
y = self.fc(x)
return y
하지만 이러한 방법 만으로는, 실험을 통하여 얻은 변수들의 관계를 명확하게 분석하고 관찰자가 놓친 부분이 있는지 등의 깊이있는 분석이 어려운 단점이 있습니다. 때문에 실질적으로는 전혀 상관관계가 없는 변수 임에도, 실험환경의 특수한 어떤 조건으로 인하여 인하여 엉뚱한 인과관계가 수치상 결과론 적으로 중요하다고 여겨지게 됩니다.
이처럼 데이터 전체를 활용하는 것이 아닌, 개별 변수들을 특정 현상의 독립적이며 실질적인 영향을 결정하는 것으로 바라보며 내용을 살펴본다면 보다 효과적인 데이터 생성 및 학습모델을 생성할 수 있게 됩니다. 이러한 분석과정을 인과추론 (Casual Inference) 라고 하고 있고 이 책은 인과추론에 대하여 파이썬 프로그래머 분들이 쉽게 다가갈 수 있는 책 입니다.

이처럼 책의 전체적인 분위기(?) 는 통계분석 도구인 R 의 통계적 이론을 활용한 인과관계 분석방법 교과서 와 유사 합니다. 그럼에도 불구하고 딱딱한 수식이 등장하면 파이썬 실습코드 예시 가 등장하여 어떠한 내용인지를 이해할 수 있게 도와주고 있고, 상세한 개념설명 부분에서는 상대적으로 생소한 통계용어로 인한 두려움이 생길 수 있는데, 옮긴이 의 주석을 통하여 상당부분 해결 가능 했습니다.
옮긴이 주석 과 저자의 용어설명 으로도 해결되지 않은 단어들을 찾아서 정리해 나가는 나만의 통계용어 사전 을 위의 예시와 같이 작성하며 내용을 진행하다 보면 이해 가능한 부분들이 저절로 늘어나는 경험을 할 수 있었습니다.
ATE(average treatment effect) : 두 그룹의 평균 차이
ATT = ATE - selection_bias (두 그룹이 완전히 동일하지 않아 발생하는 bias)
처치,처리(treatment) : 서로다른 조합에 따라 다양하게 실험하는 행위
실무에서 다룰법한 데이터를 활용하여, 기초가 부족한 독자들을 위해 개념에 대한 자세한 설명과 함께, 통계이론을 활용한 인과추론 내용에 대하여 파이썬 소스코드로 실험까지 함께 다루고 있습니다.

그리고 여러 변수들의 관계를 분석할 때 실험단계에서 놓친 내용으로 부족한 부분이 있다면 통계적 이론을 활용하여 더미변수(가변수) 를 만들이서 덧붙임으로써 실험단계를 다시 반복하지 않아도 극복 가능한 방법등도 다루고 있습니다.
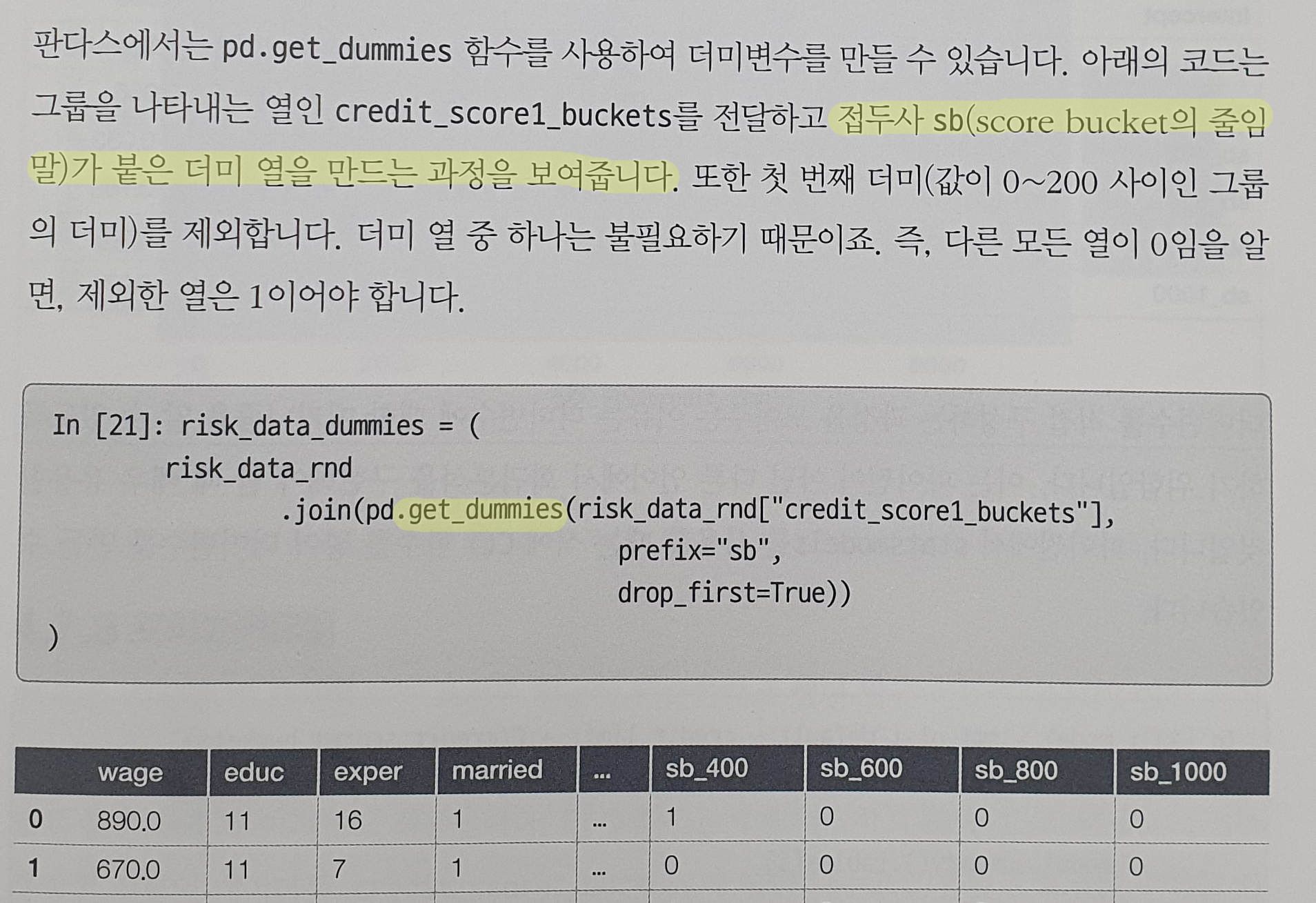
이러한 다양한 장치들로 인해 책에서 설명하고자 하는 인과추론 (Casual Inference) 에 대한 개념 및 분석이론 들을 독자들이 이해하기 쉽도록 도와주고 있습니다.
소스코드
이 책에서 사용되는 모듈은 pandas, numpy, statsmodels, seaborn 등으로 버젼에 따른 API 변화가 적은 상당히 대중적으로 사용되는 모듈들을 주로 사용하고 있습니다. 한글 변역한 가짜연구소 에서도 관리하는 github 를 제공하고 있어서 이 내용을 참고하면 대부분의 예제들은 손쉽게 진행할 수 있었습니다.
실무로 통하는 인과추론 with 파이썬 - Github (가짜연구소)
영어원서 저자의 Github 도 24년 1월에 수정된 내용이 반영될 정도로 활발하게 갱신되고 있는만큼 실습부분은 아무런 걱정없이 따라하실 수 있었습니다.
한가지 아쉬운 점은 두 주소 모두 requirements.txt 파일을 제공하고 있지 않았습니다. 때문에 각각 필요한 모듈을 사용자가 직접 설치해야 한다는 점이 있었습니다.
마무리
이 책의 각 장들은 독립적인 구성이 아닌, 마치 수학의 정석과 같이 모든 내용들이 연결되어 앞의 내용들을 보다 전문적으로 이해 가능한 내용들로 그 다음장이, 그리고 그 다음장도 동일하게 내용을 이해하려면 앞에서 다룬 내용들을 상당부분 활용하여 다음 단계를 설명하는 구조로 되어 있습니다.

때문에 앞에서 설명한 저자의 여러 기술들도 3부 이후의 뒤 내용으로 진행 될 수록 이론과 수식들의 압박(?) 강도가 강해짐에 따라 어려움이 있을 수 있는만큼 첫술에 모든 내용을 이해하기 보단 실습코드와 예시의 설명들로 머릿속에 스케치를 여러장 그리고, 실제 작업을 진행하면서 각각의 스케치들을 활용하는 방법이 가장 효율적일 것으로 생각 됩니다.
24년 3월 현재 교보문고 사이트에서 인과추론을 검색하면 발견되는 책들이 총 7권이고, 그중 인과추론에 대한 전체적인 내용을 다루는 책은 이 책이 유일 합니다. 나머지 책 중에는 R기반 성향점수분석 그리고 의학 및 사회과학 연구를 위한 통계적 인과 추론 정도가 비슷하지만 개발자 분들에게는 생소하고 인과추론의 일 부분만 다룬 책이 전부 였습니다.
본인이 조금더 효과적인 데이터 분석을 하고 싶으신 분들이라면 이 책을 꼭 읽어보시길 추천 합니다.
※ 본 리뷰는 IT 현업개발자가, 한빛미디어 책을 제공받아 작성한 서평입니다.
