빅데이터 분석은 전처리와 모델링 과정을 모두 거쳐야 하기때문에, 한 부분이라도 문제가 발생하거나 만족스럽지 못하면 처음부터 다시 접근을 해야 합니다. 이를 no free lunch theorem 이라고 합니다.

- Forcused Crawling (포커스드 크롤링) : 크롤러, 스크롤러, Agent, Spyder, Bot, 앵커 텍스트 수집분석
- Scraping (스크래핑) : 데이터를 쪼개서 원하는 영역만 수집
(수) word piece model : 데이터를 수집하고 정리하기
지도학습 : Regression (value 를 Predict) / Classification / Linear regression, Gradient Descent
비지도학습 : Clustering ex)K-means, EM, Latens Sementic, LDA 모델링
분석 : Statics (likelihood), Probability (Bayes)
NLG (Natural-language generation) : 어떻게 말을 생성하는 알고리즘을 생성할 것인가 (한글은 통사적 특징으로 잘 안된다)
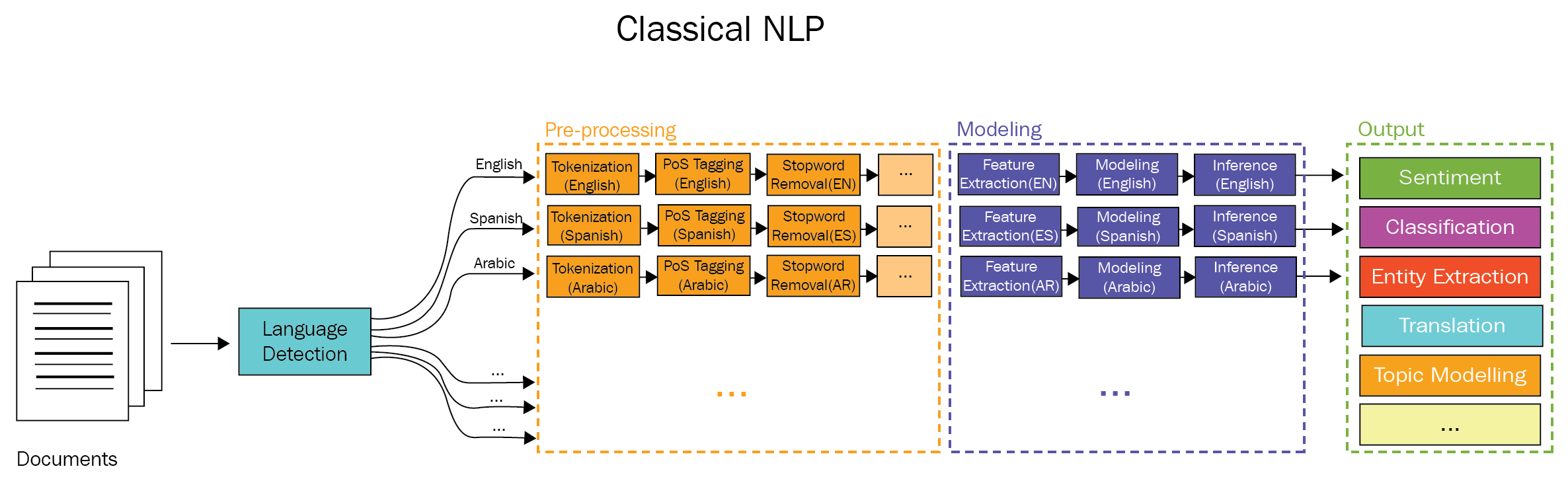
NLP 프로세스 : 해당언어 번역/ 문서수집/ 감성분석/ 정보추출/ 질문과 답 모델링 (잘 안되어서 이를 ) Human Based Profile (전문가들의 질문과 답을 찾아서 끼워맞춤) ASK.com
언어란 특정목적으로 구조화 되어 별도의 로직과 접근법이 필요
NLP 자연어 분석 개론
응용분야
- 정보검색 (map reduce), 질의응답 시스템, 인덱싱
- 기계번역, 자동통역
- 문서요약, 오탈자 검증 및 수정, 문법오류 수정
통사적 다양성 (동사의 쓰임)
- Postfix 언어 (Head-final Language)
- 동사가 문장 뒤에 위치
- 한국어, 일본어
- Infix 언어
- 동사가 문장의 중간에 위치
- 영어, 프랑스어
- Prefix 언어
- 동사가 문장의 처음에 위치
- 아일랜드어
단어를 보어로 볼것인가? 아니면 1개의 단어로 볼것인가?
자연어 분석단계
- PreProcessing
- 형태소 분석 Morphological Analysis (Regular Grammer(정규문법) 으로 분석 가능)
- 구문분석 Syntax Analysis (NER (Named-entity recognition) : 객체명 인식, 6W 를 찾는과정)
- 의미분석 Semantic Analysis <== 현재의 기술단계 ( 전자사전(wordnet), On Tology , Word2Vec )
- 화용 분석 Pragmatic Alalysis : 앞에서 사용된 사용자의 문장과 문맥 데이터를 바탕으로 문장의 해석 (대명사 해석이 어려워 아직은 난공불락)
형태소 분석의 난점
- 중의성 (ambiguity)
- 접두사, 접미사의 처리
- 고유명사, 사전에 등록되지 않은 단어의 처리

구분문석 (Syntax Analysis)
- 구문분석은 Top Down, 왼쪽에서 검색 모델링을 한글에도 적용 가능하다 (잘 된다더라..)
- 작업은 1) Tagging 2) Stemming(문법적 해석) 3) 구문분석 (구조적 모델링) 4) NER : 6W 분석을 위한 작업과정
- 단 문어체 분석 과 구어체 분석 의 경우 개별 표본에 따른 결과를 다르게 적용 가능하다
의미분석
구문분석 등의 결과 문제는 없지만 실제 의미해석시 문제가 발생하는 경우 ex) 돌이 걸어간다
khaiii
kakao의 오픈소스 Ep9 - Khaiii : 카카오의 딥러닝 기반 형태소 분석기
https://github.com/kakao/khaiii
http://tech.kakao.com/2018/12/13/khaiii/
현재의 기술수준은
- 검색, 스팸필터링, 문서분류 작업등에 자연어가 활용중..
- 매뉴얼을 찾기 쉽게 사용자들의 접근성을 높여주는 챗봇 서비스 (대화형 및 응용력 까지는 어렵다)
- 챗봇 서비스 (패턴매칭, 키워드/ 연관어 추출)
- 지능형 비서 (폐쇄형 일부, 개방형)
- 감성적 서비스 (아직은 어렵다)
Corpus 세종 21 용례 : 검색하면 안나온다!!
HTTP
- 게시판, 회원정보, 서버정보
- :80 http 기본포트
- :443 https 기본포트
Get 요청을 하면, Response 응답내용을 해석 가능 합니다. (Byte 데이터를 DOM 으로 해석), TCP/IP 방식으로 해석
request
euc-kr(국내만 표준), utf-8, ISO-8859-1
restful
get (/movies, /movies/:id), post, put, delete
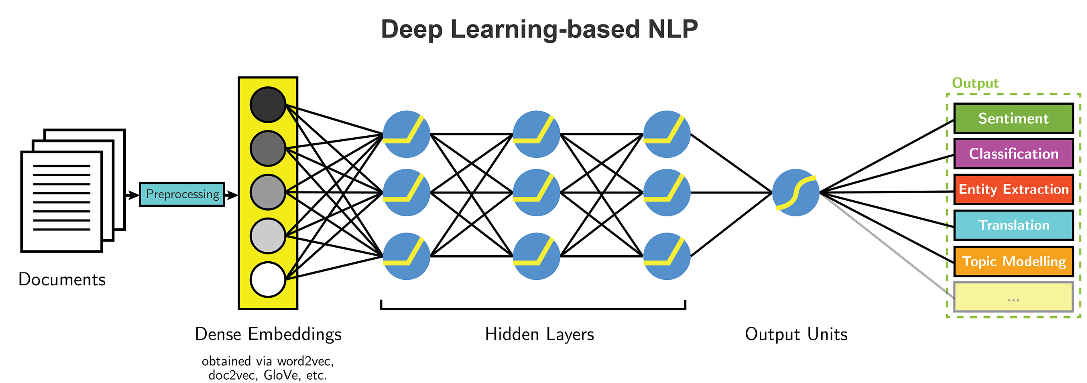
NLP 과정 :전처리 => 모델링 => 아웃풋
- 대용량 데이터로 부터 Static 한 분석방법을 활용
- 단 Black BOX 가 Rule Based 로 생성되어야 안정적인 관리가 가능하다.
- 딥러닝 과정은 낮은 과정의 차원으로 데이터를 재정의 한다
Legal Issue
- Opt-In : 명시적인 동의가 있는 부분만 수집 (White list)
- Opt-Out : 명시적인 거부내용은 수집을 중단 (Black list)
- Robots.txt : 수집기 접근을 제어하기 위한 규약
Opt-Out 검색엔진 및 가격비교 는 합법적이다. (사용자가 별도의 가공을 통해 본래의 목적을 침해하지 않는다) 단 자료의 속성이 특정기업의 DB 로 특정이 가능한 경우에는 대법원 “웹사이트 무단 크롤링은 불법” 처럼 문제가 될 수 있다.
https://news.naver.com/robots.txt 와 같은 방식으로 수집내용을 확인한다
수집하는 방법으로는
- Robots.txt : 접근제약 규칙의 준수
- Crawling delay : 최대한 서버부담 최소화
- Term of use : 사이트 이용방침
- Public content (지적 재산권 침해여부)
- Authentication-based sites (민감한 정보 수집 주의)
Selenium
xml 문법을 사용하여 필요한 DOM 내용을 조작
CSS Selector 를 사용하여 DOM 내용을 특정 합니다.
Ajax 비동기 부분을 크롤링 할 필요가 있는 경우..
- JavaScript 를 해석하거나
- 해석한 DOM 을 해석
- Ajax 통신 내용을 InterCept 한다
XML 또는 Json 형식으로 통신하는 데이터를 찾아서 작업을 하면 가장 원활하다
크롬 Network > XHR (Http 통신내용을 확인 가능)
Word Piece Modeling (3일차)
AI 는?
- Statistic NLP (검색이 주요 구성요소)
- Machine Learning
- Deep Learning
- Natural Language Processing
- 인지 심리학
자연어 분석 의 기초 구성요소
- 형태소 분석 (문법상 최소조각) tokenizing, POS Tagger, Index Term, Vecorizaion
- 구문분석 (문장경계, 개체명 사전(PLOT, 수치, 한글표기), 개체명 인식)
- 의미분석 (대용어 해소(대명사, 두문자, 약어, 수치명), 의미 중의성 해걸(동명이인))
- 담화분석 (분류(비지도), 군집(지도:주제찾기), 중복, 요약, 가중치, 순위화, 토픽모델링, 이슈트레킹, 평판분석(LDA), 감성분석, 복합논증분석)
- 중의성 해소
Ontology 대신 Word2Vec 관계를 활용하는 모델링이 대부분
Q. 색인은 태그가 아닌 뭔가? (사용자가 추가적인 인덱스를 추가한다) Q. 감정분석은 긍부정 아닌 호감도 정도 측정인가? 감성 과 감정의 차이를 구분 (희노애락의 다양한 단계들을 구분하는 분석으로 Text 분석에서 Vision 분석으로 넘어간 상태 Q. Tagging 은 개별 단어들의 내용으로 Tagging 을 할 뿐, 문장구성 요소로써 다르게 차이를 구분하진 않는다 (Mecab 은 조금 되는 듯..)
Statistic NLP 응용기술
- 검색 (통계가 주요하다)
- 온라인 광고
- 자동번역 (BERT : Byte Pare Embading 을 활용한 Stemming)
- 감정분석 (긍부정이 아니라 희노애락 다양한 단계들을 구분)
- 음성인식
- 맞춤법검사
감성 (주제에 대한 사람들의 감정과 태도),
담화 : 문단과 문단이 이어지며 형성되는 내용 (Sentence 별로 Token 을 생성해야 한다) 어절 : 개별 문장을 구성하는 단위로 어절(간) 단위로 구분 및 색인이 필요하다 (Word Tokenizing)
N-gram 모델 : 마르코프 모델링과 밀접
NLU (Under Static), NLG (Generate)
Text Mining 검색, 분류 토픽모델링 작업을 위한 NLU, NLG feacture 를 찾을 것인지를 확인하는 과정
NGRAM 을 수집한 뒤 Liklihood 값으로 Chunk 묶음을 분석하여, 개별 단어 뒤 이어질 내용의 분석이 가능하여 NLU, NLP 가 가능합니다.
Dynamic 프로그래밍에서 조건부 확룰시 개별 조건을의 확률값을 사용하기 보단, N-gram 토큰의 빈도값 실수를 활용하면 보다 유효한 데이터값이 추출 가능합니다.
Zip’s Law
경험적인 측면에서 증명된 중요도 빈도 해석방법