Doc Indexing, Ranking Model and Query Parser ,자료의 검색을 Search 대신 retrieval 단어를 사용 합니다. TDM 에 대한 자세한 설명 블로그
Search Engine
Indexer (Index 작업을 수행하는 함수들)
- Crawler (retrieval 수집)
- Doc Analyzer (빈도분석을 활용한 Vector 로 표현)
- Doc Representation
Posting File 로 저장 후 Index DataBase 에 저장
USER == (Query)==> Query Pep
Token 간의 Ranker (relavent 관계를 기준으로) = > 검색 결과를 출력
User relevant Feedback (Evaluation) => 사용자들의 Feedback 정보로 개인화 맞춤형 서비스
정보의 Retriver 방식들
- ad hoc 방식 : 고정된 데이터에 사용자의 요구에 따라 쿼리가 변경
- Filtering (추천시스템) : 사용자의 요구는 동일하지만 데이터가 계속적으로 가중치를 변경
CS4501
Bag of Words 를 One-HOT-Encoding 으로 구현하면 낭비되는 공간이 많다
Information retrieval
Space Complexity Analysis 최고차항 공식 디노테이션 : O (D(문서의 모든 token의 수) * V (Dimension))
차원의 축소 (벡터 공간을 줄이는 방법)
Solution : Token 인덱스를, 주소값 인덱스로 치환
Linked List for each document (Map Reduce 방식을 적용)
Time Complexity Analysis
DTM word1 word2 … => doc1 0 1 doc2 => D(Collection)
(Trans pose Vector) TDM doc1 doc2 … => D(Collection) word1 0 word2 1 word3 => V |Q| *D, Linked List
word1, ptr => doc2, prt
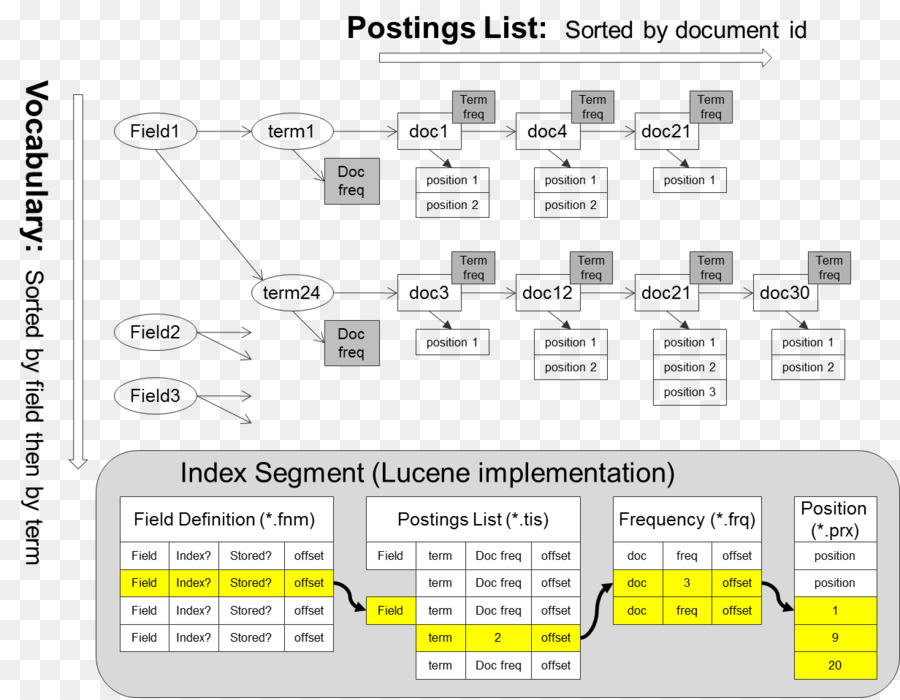
Inverted Index
Token 의 인덱스만 저장하고, 인덱싱 주소만 활용하여 Posting 구조를 만든다
각각의 Term 에 대한 관계를 역으로 바꿔서 데이터를 재정의 합니다 (Query : )
DBM : B-Tree 구조로 만들어서 (Valanced Tree 구조)
Map Reduce 구조
Sorting Based Inverted Index Construction
Ranking
문서별 가중치를 할당하여 관계를 검색합니다
대표적인 방식으로 Vector Space 방식이 가능합니다
Vector space model
Vocabluary 갯수만큼의 차원의 공간에 nlp를 배치한다
Document 와 Query 를 차원 내부에 자료들을 정렬 합니다.
Cosin Angle 을 활용하여 문장간의 유사도(similarity) 등을 측정 합니다.
Orthogonal : Bag of Word 모델과 표현하기 용이성이 높다.
빈도를 기반으로 확률(Liklihood, Conditional Probability) 데이터를 활용 ex) Naive Bayse 방식으로 Graphical Modeling (LDA 모델링)
How to assign Weight
Token 들의 중요도 측정방법 : Weight ex) Zif’s Law (고빈도와 Rare 빈도는 제거함이 용이하다)
Vector 를 구성하는 Concept 을 추출하는 방법에 용이
Heuristics (ex> Tf-IDF : 안정적인 모델링이 가능) : 사람의 경험을 바당으로 만들어지는 만큼 다양한 변종이 가능하다
Orthogonal (상호 독립적 : 내적의 결과가 0)
Ambiguity 하지 않은 결과를 도출 가능하다 (Bag of Word 개념과 밀접한 관계)
Bag of Word : 모든 단어들은 Indipendent 하다는 전제에서 모델을 생성
King - Queen
Word Embadding (주변 단어를 활용하여 중심 단어를 찾는다 : Topic Modeling)
단어간 Relevality(연관성) 이 높은 경우가 있다.
ex) N-gram, Topic Modeling 이 대부분의 분석방법에 활용
Tf weight (Tf-IDF)
TF : 문서 내 중요도를 판단 (빈도수 기준)
한계가 있다
Tf Normalization
- SubLinear TF Scaling (Log 를 활용한 방법으로 Base 미만의 값은 보정을 한다)
- Maximun TF Scaling (1번을 보완한 모델로 Max() 값을 활용) alpha 는 보정값 (초기값이 너무 작은 단어들을 Smoothing 보정값 ex)0.5)
Document Frequency
Zif’s Law 에서 중빈도 Token 을 특정하는 방법
때문에 불필요한 단어들이 반복될 떄 (ex> 기자) 지워주는 방법으로 활용 가능하다
IDF weight
max (토근을 무관하고)
엔트로피가 작을수록, Targeting 이 용이해 식별력이 높은 단어로 중요도가 높아진다.. (잘 알아들었제??)
Normalization : 문서내 빈도가 가장 많은 숫자로 정규화를 진행합니다. (문서별 tf 값을 바로 적용하지 않고 전처리 작업을 진행합니다)
Zif’s Law 를 근거로 IDF 보정결과가 중요도 높은 자료를 추출하는데 효과적임이 증명된다.
Euclidean Distance
Query 값이 문서에서 참고 목록
값이 작을수록 유사도가 높은 문서들로 분류가 가능하다
하지만 Document 의 단어들이 많을수록 유사도 측정시 패널티가 생겨서 실제로 유사도 결과에 문제가 생긴다
문서가 길면 길수록 거리가 멀어진다
dist(q,d) =

Inversed Index Model
Posting (file / on disk)
Vocabulary
Token1 prt Token2 prt Token3 prt
Question
Q. Page Rank 란? Q. Log TF : DOC1, 2 ,3 내부에서 t,d 는? Q. Document Vector 는? Q. 유클리드 거리 유사도 측정시 TOken 갯수로 인한 패널티는?
IDF :