UnSupervised Learning (비지도 학습방법) 을 알아봅니다. 예로들면 Social 상황에서 어떤 주제로, 비중의 계산 및 긍정/ 부정 여부를 규정화 된 틀에 따라 자동으로 분류를 하게 됩니다.
Supervised Learning
you know the true value.
you provide examples of the true value.
UnSupervised Learning
you don’t know the true value.
you can’t provide examples of the true value.
K-Means
Hard Clustering 대표적인 기법 (Soft Clustering 은 확률을 기준으로 분류하는 알고리즘으로 Gausiam Mixed 알고리즘 등이 있습니다) 입니다. (Pointer 가 특정되어 변경되지 않습니다)
EM Algorithm 은 반복이 많아서 속도적인 측면에서 단점이 존재합니다.
손실함수 J 는 Sum Squared Error 값으로 이웃으로 분류된 점들과 거리를 측정 합니다. 이렇게 측정된 손실함수가 Minimize 된 값을 찾는 방식으로 반복실습하여 측정결과를 분류 합니다.
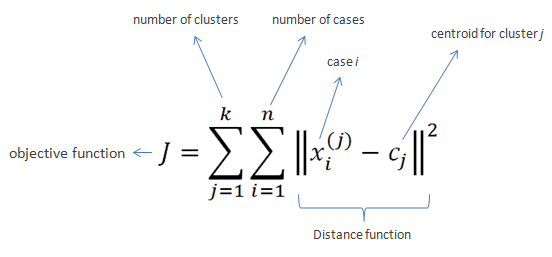
r_(n,k) = {0,1} 는 n(데이터 포인터) k(클러스터의 수) 로 0 또는 1로 구성됩니다. 클러스터에 포함되면 1, 비해당시 0의 값을 갖습니다.
r_(n,k)(클러스터 포함 포인트 수) , Mu_k(중심 포인트) 를 찾아서 최적의 함수를 결정합니다. 구해야 하는 값이 2개여서 여러번의 시행착오를 필요로 합니다. r_(n,k) 를 특정한 뒤 Mu_k 를 측정하는 반복과정을 통해서 최소의 J 를 갖는 변수값들을 찾아냅니다.
Bayse 방식을 사용하면 효과적인 K 갯수를 추정할 수 있지만, 손실함수 J 가 일정한 값으로 수렴하는 만큼 효과적인 차이는 크지 않습니다.
클러스터링 결과는 수치적인 결과일 뿐, 의미적인 분석은 Huristic 방식으로 해석의 과정을 필요로 합니다. * Expactation, Maximise => Expactation, Maximise … 를 반복하면서 Sum Squared Error 반복을 통해서 최적의 분류 모델을 생성합니다.
K-Means++ 는 분포의 값을 측정하여 보정 후 최적의 값을 찾는 방식입니다
Limitation of distance Metrics : 각도를 활용하는 경우에도 평균값을 사용하면 됩니다
K-Means Process
r_(n,k) 는 반복을 통해서 값을 찾습니다.
Question!! Q. 그말은 K-means 는 분포를 별도로 최적화 하진 않는다는 뜻인가? Q. Hard Clustering : 분류의 기준이 절대값 경로를 갖는다는 뜻? 반대는 상대경로인가?
작업 후 Question!! Q. 정확하기 Dk 는 뭔가? : Mu 는 각 축별로 있어서 이 값을 사용해 K 가 보정된다 Q. Estimate 함수는 K 의 좌표를 어떻게 새롭게 갱신하나? Q. Cosine 거리는 최대값이 기준인데, 원점에서 어떻게 개별 포인트가 특정되나? : Cosine 의 기준은 각 K 벡터이고, 개별 값들이 K와 각도를 계산해서 가까운 점들끼리 모입니다.
라그랑지승수
\[A^2 + B^2 = C^2\] \[a^2 + b^2 = c^2\]