책도 얇고, 그림이 많아서 내용에 대해 기대를 안했었는데, 생각보다 알찬내용과 기존에 잘 이해하지 못했던 부분들을 잘 연결해 주고 있어서 만족한 도서 입니다. 저자가 한국어 임베딩 을 작성했던 분으로 자연어 논문들을 번역한 사이트 를 운영하는 분이였습니다.
자연어 처리에 대한 기본개념의 설명과, 한글 데이터 예제들을 제공함으로써 앞서 리뷰를 했던 트랜스포머를 활용한 자연어 처리 에서 느꼈던 부족한 부분들을 모두 채워주는 내용이었습니다.
1장 처음 만나는 자연어 처리
1-1 딥러닝 기반 자연어 처리 모델
컴퓨터 학습 기본모델
입력 -> $f(x)$ 모델(함수) -> 출력(확률)
*감성(sentiment)분석 모델 : 문장의 긍정(positive), 중립(neutral), 부정(negative) 확률
\(\begin{align}
f(`재미가 없는 편인 영화`) = [0.0, 0.3, \textcolor{orange}{0.7}] \rightarrow 부정
\end{align}\)
\(\begin{align}
f(`단언컨대 이 영화 재미 있어요`) = [\textcolor{orange}{1.0}, 0.0, 0.0] \rightarrow 긍정
\end{align}\)
1-2 트랜스퍼 러닝
기존에 학습한 모델을 다른 Task 수행을 위해 재활용하는 기법 입니다. 최종목표인 Task 에 필요한 모델을 학습하면서 PreTraining 경험을 재활용 하는데, PreTraining 을 UpStream, Task 를 DownStream 라고 부릅니다.
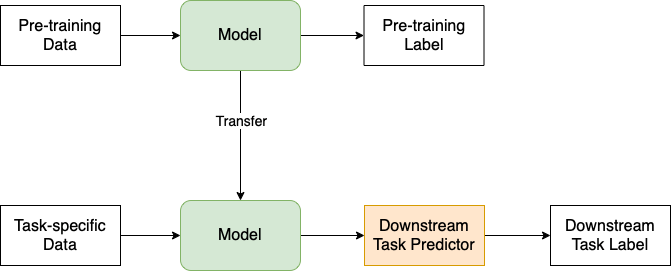
UpStream Task
GPT 계열의 모델들이 수행하는 내용으로 다음 단어 맞추기, 또는 빈칸 단어 맞추기 가 있습니다. 대규모 말뭉치 데이터를 활용하여 반복 학습을 실시 합니다. 이렇게 수행한 모델을 언어모델 (Language Model) 이라고 합니다. 그리고 이처럼 데이터 내에서 정답을 만든 뒤 학습하는 모델을 자기지도 학습(Supervised Learning) 이라고 합니다.
</a>
DownStream Task
궁극적인 목적은 DownStream Task 를 잘 수행하는 것입니다. 일반적으로는 UpStream 모델을 구조변경없이 그대로 사용 하거나, 또는 Task를 덧붙이는 형태 로 수행합니다. 문장생성형 Task 를 제외하면 Bert 계열을 사용합니다.
이번 책은 Fine-Tuning 을 활용하는데 그 내용은 Bert 모델 전체를 문서분류(긍/부정), 자연어 추론(두 문장사이 관계 참/거짓), 개체명 인식(단어가 속한 카테고리 분류), 질의응답(질문/응답 문장간의 확률), 문장 생성(문장 입력받아, 각 어휘에 대한 확률값으로 문장생성) 등의 최종 Task 데이터로 업데이트 합니다.
HugginFace DataSet & Cache
HuggingFace 에서 제공하는 모델은 500mb 그 이상의 크기를 갖기 때문에, 여러 데이터를 실습하다보면 캐시 데이터가 쌓이게 됩니다. 사용자 정의에 따라 해당 폴더를 삭제하거나 바꿀수 있는데 세부 내용은 위 링크내용을 참고 합니다.
$ ~/.cache/huggingface ➭ du -h --max-depth=1 .
4.5G ./hub
11M ./datasets
80K ./modules
4.5G .