Pytorch 모듈을 활용하는 머신러닝 유 경험자 에게 가장 쉽게 고급 자연어 원리를 학습하는데 도움이 많이 되는 책 입니다.
총평
Hugging Face에서 미리 학습한 학습 데이터 와, 잘 정돈된 데이터셋 을 활용함으로써 빠르게 진도를 진행할 수 있었습니다.- 파이토치로 배우는 자연어 처리 (한빛미디어, 2021) 와 비교를 하자면, 코드와 이론의 상세한 설명 보다는, 그림을 활용한 전체적인 개념의 설명과 함께, 직관적인
API로 구성된 Tutorial 들로 인해서 1독을 하는데는 훨씬 수월하게 진행할 수 있었습니다. Pandas, Numpy, Pytorch모듈에 대한 기본 개념은 따로 익혀야 하고, 챕터마다 미리 학습한 모델과 데이터셋을 수시로 다운받아서 진행을 하기 때문에, 작업을 수행하는 HDD 의 용량이 최소한 80Gb 이상은 확보가 되어 있어야 합니다.
In[0]
text = """Dear Amazon, last week I ordered an Optimus Prime action figure \
from your online store in Germany. Unfortunately, ...(중략) ..."""
from transformers import pipeline
classifier = pipeline("text-classification")
classifier(text)
Out[0]
[{'label': 'NEGATIVE', 'score': 0.9015461802482605}]
In[1]
summarizer = pipeline("summarization")
outputs = summarizer(text, max_length=60, clean_up_tokenization_spaces=True)
print(outputs[0]['summary_text'])
Out[1]
Bumblebee ordered an Optimus Prime action figure from your ... (중략) ...
데이터 셋
전체적으로 Hugging face 에서 제공하는 데이터와 모델을 활용함으로써, 데이터셋 구조 자체가 일관되고 이미 잘 구축된 자료를 활용하고 있어서 이 부분에 있어서는 전혀 문제가 발생하지 않았습니다.
사용자가 임의로 작성한 데이터를 활용하데 도움이 되는 API 를 함께 소개 하고 있었습니다. 한글로 작업한 자료를 실습하는 과정을 책에서 직접적으로 다루고 있지는 않지만, 아래의 예시등을 통해서 어떻게 자료를 정리하고, 정리된 데이터를 학습에 활용하는지 까지는 상세하게 잘 다루고 있었습니다.
url = "https://huggingface.co/datasets/transformersbook/emotion-train-split/raw/main/train.txt"
!wget {url}
emotions_local = load_dataset(
"csv", data_files="train.txt", sep=";", names=["text", "label"])
57p 의 내용으로, 번역가 1인이 관리하는 git repository 으로 인해 다운로드 가능한 Link 가 변경 되었음에도 국내 번역 자료에는 반영이 되지 못하는 부분이 있었습니다, 따라서 영어 원서 저자의 GitHub nlp-with-transformers / notebooks 도 함께 확인을 하면서 진행을 한다면, 진행 중 문제가 발생하더라도 어렵지 않게 진행할 수 있었습니다.
개념의 설명
호불호가 가장 크게 나뉠 부분이 개념의 설명 인데, 이 책은 수식을 최소화 하고, 그림을 활용하는 개념들 관의 관계와 역활을 설명하는 방식 으로 구성이 되어 있습니다. 개인적으로는 Coding 을 따라하는데 있어서 상세한 수식은 컴퓨터가 알아서 계산을 해 주기 때문에, 상세한 수식의 내용과 결과값의 설명 보다는 이 책과 같이 대략적인 개념들의 관계와 역활을 이해한 뒤, 상세한 세부 내용은 fine tuning 과정을 통해 상세하게 이해를 하는 방법이 좋다고 생각하고 있어서, 이러한 설명 방법은 다른 책과는 차별화 되는 장점으로 받아들여 졌습니다.
구체적인 예로 전이학습 과 트랜스 포머 의 인코더 와 디코더 구조 의 개념을 설명하는 부분은 다음과 같습니다.
책의 98P 내용으로, CNN, RNN, Attention 등의 개념을 다른 도서와 달리 수식을 통한 이해를 억지로 진행하려고 하기 보다는, 대략적인 모델의 시각화를 통한 전체적인 구조와 각각의 개념 들을 설명하고, 각각의 구성요소를 소스 코드를 실습 함으로써 이해할 수 있도록 구성되어 있어서 다른 책들과 비교해서 비교적(?) 빠르게 내용들을 이해하며 진행할 수 있었습니다.
딥러닝과 관련하여 전혀 이해가 없는 분들에게는 이같은 내용이 불친절한 설명들로 인해 어렵겠지만, 퍼셉트론, CNN, RNN 의 구조에 대해서 만큼은 상세하게 이해를 한 독자 들이라면 (Attention 까지 이해를 하면 더 좋겠지만 ... ) 이들 기본적인 3가지 신경망 개념을 바탕으로, 책에서 설명하는 추가적인 기능들이 덧 붙여서 작동을 하는구나 하는 식으로 진행할 수 있게 잘 구성되어 있었습니다.
모델의 설명
자연처 처리방법론들 마다 다뤄지는 학습모델 이론 중 중요한 개념은 위의 설명처럼 그림으로 나마 설명이 진행되고 있지만, 나머지 다양한 모델들은 Chapter 6 요약 에서 처럼, 간략한 설명과 함께 구현가능한 예시 코드를 나열하는 방법으로 간략하게 진행되고 있었습니다.
책에서 다루지 못한 내용들
규모가 작은 Toy 모델을 생성하는 과정을 A 부터 Z 까지 다뤄 줬으면 좋았을텐데, 이 부분은 앞에서도 언급한 파이토치로 배우는 자연어 처리 (한빛미디어, 2021) 등의 다른 자료를 참고해야 합니다. 즉 이 책은 새로운 모델을 만드는 것 보다는, 이미 만들어서 제공하는 모델들의 설명과 활용방법에 중점을 더 높이 두고 있습니다.
그리고 원서를 번역한 내용인 만큼, 한글 데이터와 모델 을 활용한 예시는 별도로 찾아서 작업을 해야 합니다.
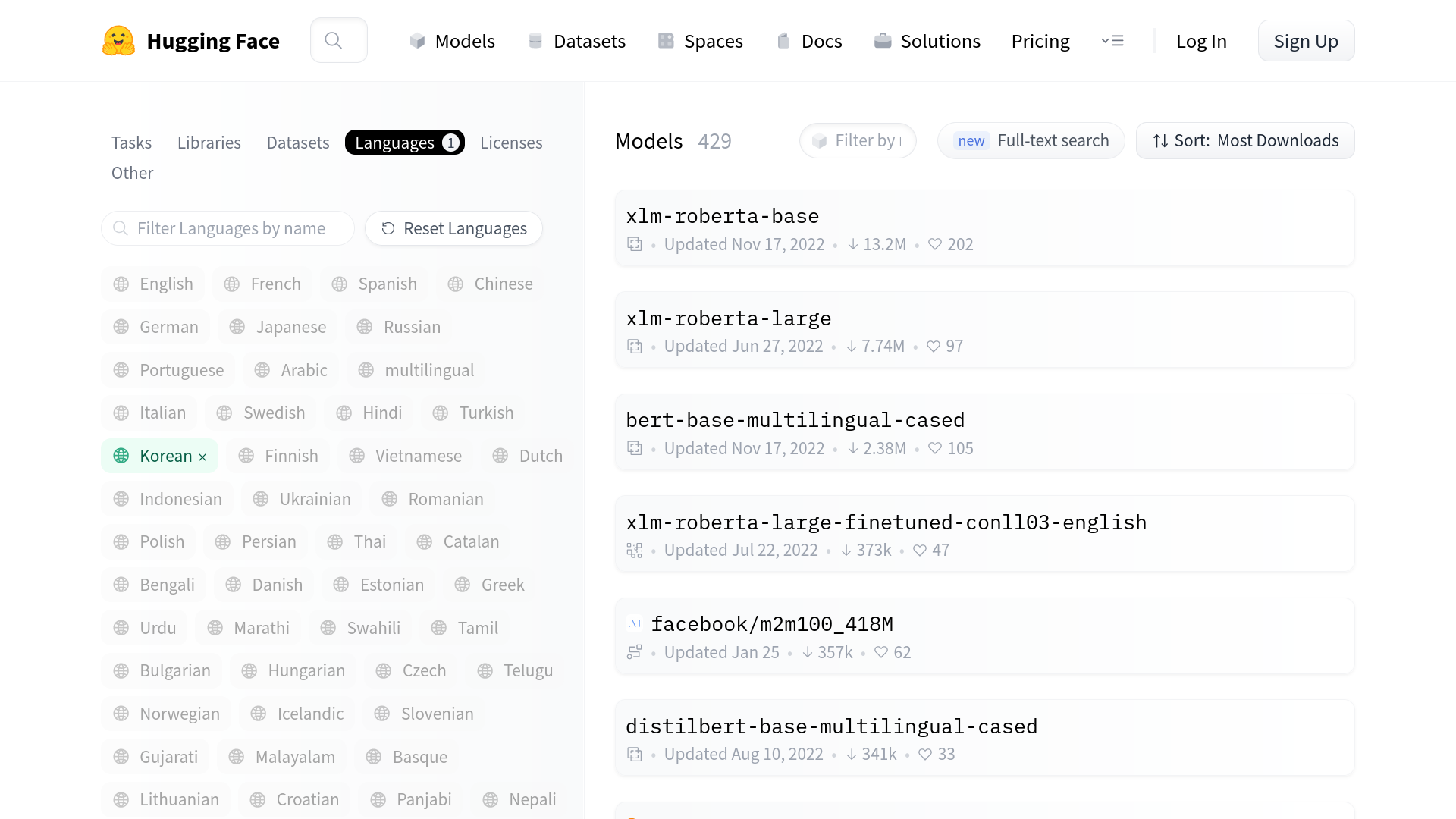
Hugging face 사이트 에서는 2023년 3월 현재 429개 의 한글을 활용 가능한 학습 모델을 다운 받을 수 있습니다. 각각의 모델들을 테스트 하고 실습하는 과정은 이 책을 참고삼아 사용자 별로 테스트 및 확인 과정이 추가로 필요 합니다.
마무리
최근 ChatGPT 이슈로 인해 이 책을 보려고 하는 분들이 많으실 텐데, 생각보다 간결한 소스코드로 인해 다른 어떤 자료보다 빠르게 내용을 실습하고 구현하는데 도움이 많이 되는 책입니다. 물론 파이썬 기초를 이해하신 분들에게는 어려울 수 밖에 없음을 책의 첫 장 첫 페이지에서 언급할 정도로 기본도서라기 보다는, 실습 및 실전 작업을 진행하는데 길잡이가 되는 책으로써 도움이 되는 책 이었습니다.
※ 본 리뷰는 IT 현업개발자가, 한빛미디어 책을 제공받아 작성한 서평입니다.
